inpainting¶
Summary¶
Number of checkpoints: 9
Number of configs: 12
Number of papers: 6
ALGORITHM: 6
Stable Diffusion (2022)¶
Task: Text2Image, Inpainting
Abstract¶
Stable Diffusion is a latent diffusion model conditioned on the text embeddings of a CLIP text encoder, which allows you to create images from text inputs. This model builds upon the CVPR’22 work High-Resolution Image Synthesis with Latent Diffusion Models. The official code was released at stable-diffusion and also implemented at diffusers. We support this algorithm here to facilitate the community to learn together and compare it with other text2image methods.

A mecha robot in a favela in expressionist style |

A Chinese palace is beside a beautiful lake |

A panda is having dinner at KFC |
Pretrained models¶
| Model | Task | Dataset | Download |
|---|---|---|---|
| stable_diffusion_v1.5 | Text2Image | - | - |
| stable_diffusion_v1.5_tomesd | Text2Image | - | - |
| stable_diffusion_v1.5_inpaint | Inpainting | - | - |
We use stable diffusion v1.5 weights. This model has several weights including vae, unet and clip.
You may download the weights from stable-diffusion-1.5 and change the ‘from_pretrained’ in config to the weights dir.
Download with git:
git lfs install
git clone https://huggingface.co/runwayml/stable-diffusion-v1-5
Quick Start¶
Running the following codes, you can get a text-generated image.
from mmengine import MODELS, Config
from torchvision import utils
from mmengine.registry import init_default_scope
init_default_scope('mmagic')
config = 'configs/stable_diffusion/stable-diffusion_ddim_denoisingunet.py'
config = Config.fromfile(config).copy()
## change the 'pretrained_model_path' if you have downloaded the weights manually
## config.model.unet.from_pretrained = '/path/to/your/stable-diffusion-v1-5'
## config.model.vae.from_pretrained = '/path/to/your/stable-diffusion-v1-5'
StableDiffuser = MODELS.build(config.model)
prompt = 'A mecha robot in a favela in expressionist style'
StableDiffuser = StableDiffuser.to('cuda')
image = StableDiffuser.infer(prompt)['samples'][0]
image.save('robot.png')
To inpaint an image, you could run the following codes.
import mmcv
from mmengine import MODELS, Config
from mmengine.registry import init_default_scope
from PIL import Image
init_default_scope('mmagic')
config = 'configs/stable_diffusion/stable-diffusion_ddim_denoisingunet-inpaint.py'
config = Config.fromfile(config).copy()
## change the 'pretrained_model_path' if you have downloaded the weights manually
## config.model.unet.from_pretrained = '/path/to/your/stable-diffusion-inpainting'
## config.model.vae.from_pretrained = '/path/to/your/stable-diffusion-inpainting'
StableDiffuser = MODELS.build(config.model)
prompt = 'a mecha robot sitting on a bench'
img_url = 'https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png' ## noqa
mask_url = 'https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png' ## noqa
image = Image.fromarray(mmcv.imread(img_url, channel_order='rgb'))
mask = Image.fromarray(mmcv.imread(mask_url)).convert('L')
StableDiffuser = StableDiffuser.to('cuda')
image = StableDiffuser.infer(
prompt,
image,
mask
)['samples'][0]
image.save('inpaint.png')
Use ToMe to accelerate your stable diffusion model¶
We support tomesd now! It is developed based on ToMe, an efficient ViT speed-up tool based on token merging. To work on with tomesd in mmagic, you just need to add tomesd_cfg to model as shown in stable_diffusion_v1.5_tomesd. The only requirement is torch >= 1.12.1 in order to properly support torch.Tensor.scatter_reduce() functionality. Please do check it before running the demo.
...
model = dict(
type='StableDiffusion',
unet=unet,
vae=vae,
enable_xformers=False,
text_encoder=dict(
type='ClipWrapper',
clip_type='huggingface',
pretrained_model_name_or_path=stable_diffusion_v15_url,
subfolder='text_encoder'),
tokenizer=stable_diffusion_v15_url,
scheduler=diffusion_scheduler,
test_scheduler=diffusion_scheduler,
tomesd_cfg=dict(
ratio=0.5))
The detailed settings for tomesd_cfg are as follows:
ratio (float): The ratio of tokens to merge. For example, 0.4 would reduce the total number of tokens by 40%.The maximum value for this is 1-(1/(sx*sy)). By default, the max ratio is 0.75, usually <= 0.5 is recommended. Higher values result in more speed-up, but with more visual quality loss.max_downsample (int): Apply ToMe to layers with at most this amount of downsampling. E.g., 1 only applies to layers with no downsampling, while 8 applies to all layers. Should be chosen from 1, 2, 4, 8. 1, 2 are recommended.sx, sy (int, int): The stride for computing dst sets. A higher stride means you can merge more tokens, default setting of (2, 2) works well in most cases.sxandsydo not need to divide image size.use_rand (bool): Whether or not to allow random perturbations when computing dst sets. By default: True, but if you’re having weird artifacts you can try turning this off.merge_attn (bool): Whether or not to merge tokens for attention (recommended).merge_crossattn (bool): Whether or not to merge tokens for cross attention (not recommended).merge_mlp (bool): Whether or not to merge tokens for the mlp layers (especially not recommended).
For more details about the tomesd setting, please refer to Token Merging for Stable Diffusion.
Then following the code below, you can evaluate the speed-up performance on stable diffusion models or stable-diffusion-based models (DreamBooth, ControlNet).
import time
import numpy as np
from mmengine import MODELS, Config
from mmengine.registry import init_default_scope
init_default_scope('mmagic')
_device = 0
work_dir = '/path/to/your/work_dir'
config = 'configs/stable_diffusion/stable-diffusion_ddim_denoisingunet-tomesd_5e-1.py'
config = Config.fromfile(config).copy()
## ## change the 'pretrained_model_path' if you have downloaded the weights manually
## config.model.unet.from_pretrained = '/path/to/your/stable-diffusion-v1-5'
## config.model.vae.from_pretrained = '/path/to/your/stable-diffusion-v1-5'
## w/o tomesd
config.model.tomesd_cfg = None
StableDiffuser = MODELS.build(config.model).to(f'cuda:{_device}')
prompt = 'A mecha robot in a favela in expressionist style'
## inference time evaluation params
size = 512
ratios = [0.5, 0.75]
samples_perprompt = 5
t = time.time()
for i in range(100//samples_perprompt):
image = StableDiffuser.infer(prompt, height=size, width=size, num_images_per_prompt=samples_perprompt)['samples'][0]
if i == 0:
image.save(f"{work_dir}/wo_tomesd.png")
print(f"Generating 100 images with {samples_perprompt} images per prompt, without ToMe speed-up, time used : {time.time() - t}s")
for ratio in ratios:
## w/ tomesd
config.model.tomesd_cfg = dict(ratio=ratio)
sd_model = MODELS.build(config.model).to(f'cuda:{_device}')
t = time.time()
for i in range(100//samples_perprompt):
image = sd_model.infer(prompt, height=size, width=size, num_images_per_prompt=samples_perprompt)['samples'][0]
if i == 0:
image.save(f"{work_dir}/w_tomesd_ratio_{ratio}.png")
print(f"Generating 100 images with {samples_perprompt} images per prompt, merging ratio {ratio}, time used : {time.time() - t}s")
Here are some inference performance comparisons running on single RTX 3090 with torch 2.0.0+cu118 as backends. The results are reasonable, when enabling xformers, the speed-up ratio is a little bit lower. But tomesd still effectively reduces the inference time. It is especially recommended that enable tomesd when the image_size and num_images_per_prompt are large, since the number of similar tokens are larger and tomesd can achieve better performance.
| Model | Task | Dataset | Download | xformer | Ratio | Size / Num images per prompt | Time (s) |
|---|---|---|---|---|---|---|---|
| stable_diffusion_v1.5-tomesd | Text2Image | - | - | w/o | w/o tome 0.5 0.75 |
512 / 5 | 542.20 427.65 (↓21.1%) 393.05 (↓27.5%) |
| stable_diffusion_v1.5-tomesd | Text2Image | - | - | w/ | w/o tome 0.5 0.75 |
512 / 5 | 541.64 428.53 (↓20.9%) 396.38 (↓26.8%) |

w/o ToMe |

w/ ToMe Speed-up (token merge ratio=0.5) |

w/ ToMe Speed-up (token merge ratio=0.75) |
Comments¶
Our codebase for the stable diffusion models builds heavily on diffusers codebase and the model weights are from stable-diffusion-1.5.
Thanks for the efforts of the community!
Citation¶
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{bolya2023tomesd,
title={Token Merging for Fast Stable Diffusion},
author={Bolya, Daniel and Hoffman, Judy},
journal={arXiv},
year={2023}
}
@inproceedings{bolya2023tome,
title={Token Merging: Your {ViT} but Faster},
author={Bolya, Daniel and Fu, Cheng-Yang and Dai, Xiaoliang and Zhang, Peizhao and Feichtenhofer, Christoph and Hoffman, Judy},
booktitle={International Conference on Learning Representations},
year={2023}
}
AOT-GAN (TVCG’2021)¶
Task: Inpainting
Abstract¶
State-of-the-art image inpainting approaches can suffer from generating distorted structures and blurry textures in high-resolution images (e.g., 512x512). The challenges mainly drive from (1) image content reasoning from distant contexts, and (2) fine-grained texture synthesis for a large missing region. To overcome these two challenges, we propose an enhanced GAN-based model, named Aggregated COntextual-Transformation GAN (AOT-GAN), for high-resolution image inpainting. Specifically, to enhance context reasoning, we construct the generator of AOT-GAN by stacking multiple layers of a proposed AOT block. The AOT blocks aggregate contextual transformations from various receptive fields, allowing to capture both informative distant image contexts and rich patterns of interest for context reasoning. For improving texture synthesis, we enhance the discriminator of AOT-GAN by training it with a tailored mask-prediction task. Such a training objective forces the discriminator to distinguish the detailed appearances of real and synthesized patches, and in turn, facilitates the generator to synthesize clear textures. Extensive comparisons on Places2, the most challenging benchmark with 1.8 million high-resolution images of 365 complex scenes, show that our model outperforms the state-of-the-art by a significant margin in terms of FID with 38.60% relative improvement. A user study including more than 30 subjects further validates the superiority of AOT-GAN. We further evaluate the proposed AOT-GAN in practical applications, e.g., logo removal, face editing, and object removal. Results show that our model achieves promising completions in the real world. We release code and models in this https URL.
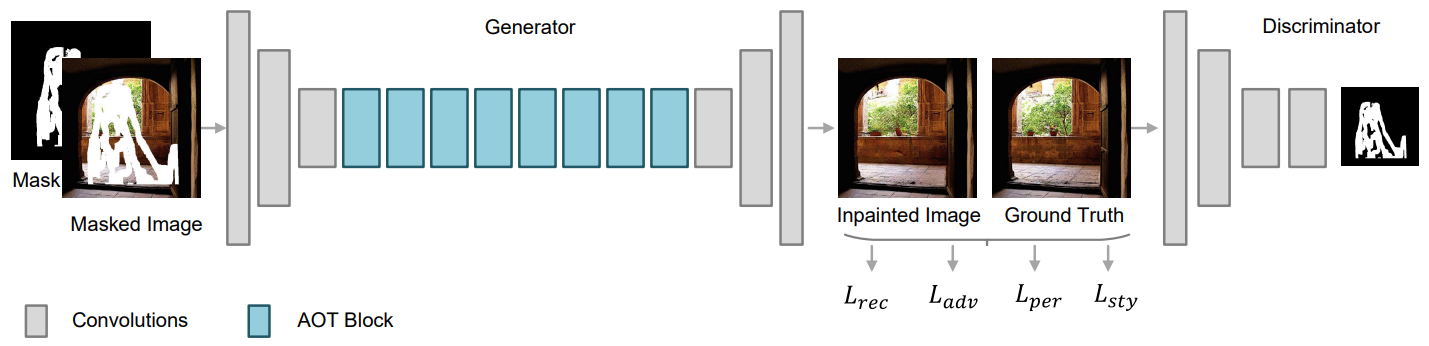
Results and models¶
| Model | Dataset | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| AOT-GAN | Places365-Challenge | free-form (50-60%) | 512x512 | 500k | Places365-val | 7.07 | 19.01 | 0.682 | 4 (GeForce GTX 1080 Ti) | model | log |
More results for different mask area:
| Metric | Mask Area | Paper Results | Reimplemented Results |
|---|---|---|---|
| L1 (10^-2) | 1 – 10% | 0.55 | 0.54 |
| (lower better) | 10 – 20% | 1.19 | 1.47 |
| 20 – 30% | 2.11 | 2.79 | |
| 30 – 40% | 3.20 | 4.38 | |
| 40 – 50% | 4.51 | 6.28 | |
| 50 – 60% | 7.07 | 10.16 | |
| PSNR | 1 – 10% | 34.79 | inf |
| (higher better) | 10 – 20% | 29.49 | 31.22 |
| 20 – 30% | 26.03 | 27.65 | |
| 30 – 40% | 23.58 | 25.06 | |
| 40 – 50% | 21.65 | 23.01 | |
| 50 – 60% | 19.01 | 20.05 | |
| SSIM | 1 – 10% | 0.976 | 0.982 |
| (higher better) | 10 – 20% | 0.940 | 0.951 |
| 20 – 30% | 0.890 | 0.911 | |
| 30 – 40% | 0.835 | 0.866 | |
| 40 – 50% | 0.773 | 0.815 | |
| 50 – 60% | 0.682 | 0.739 |
Quick Start¶
Train
Train Instructions
You can use the following commands to train a model with cpu or single/multiple GPUs.
## cpu train
CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py
## single-gpu train
python tools/train.py configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py
## multi-gpu train
./tools/dist_train.sh configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py 8
For more details, you can refer to Train a model part in train_test.md.
Test
Test Instructions
You can use the following commands to test a model with cpu or single/multiple GPUs.
## cpu test
CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py https://download.openmmlab.com/mmediting/inpainting/aot_gan/AOT-GAN_512x512_4x12_places_20220509-6641441b.pth
## single-gpu test
python tools/test.py configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py https://download.openmmlab.com/mmediting/inpainting/aot_gan/AOT-GAN_512x512_4x12_places_20220509-6641441b.pth
## multi-gpu test
./tools/dist_test.sh configs/aot_gan/aot-gan_smpgan_4xb4_places-512x512.py https://download.openmmlab.com/mmediting/inpainting/aot_gan/AOT-GAN_512x512_4x12_places_20220509-6641441b.pth 8
For more details, you can refer to Test a pre-trained model part in train_test.md.
Citation¶
@inproceedings{yan2021agg,
author = {Zeng, Yanhong and Fu, Jianlong and Chao, Hongyang and Guo, Baining},
title = {Aggregated Contextual Transformations for High-Resolution Image Inpainting},
booktitle = {Arxiv},
pages={-},
year = {2020}
}
DeepFillv2 (CVPR’2019)¶
Task: Inpainting
Abstract¶
We present a generative image inpainting system to complete images with free-form mask and guidance. The system is based on gated convolutions learned from millions of images without additional labelling efforts. The proposed gated convolution solves the issue of vanilla convolution that treats all input pixels as valid ones, generalizes partial convolution by providing a learnable dynamic feature selection mechanism for each channel at each spatial location across all layers. Moreover, as free-form masks may appear anywhere in images with any shape, global and local GANs designed for a single rectangular mask are not applicable. Thus, we also present a patch-based GAN loss, named SN-PatchGAN, by applying spectral-normalized discriminator on dense image patches. SN-PatchGAN is simple in formulation, fast and stable in training. Results on automatic image inpainting and user-guided extension demonstrate that our system generates higher-quality and more flexible results than previous methods. Our system helps user quickly remove distracting objects, modify image layouts, clear watermarks and edit faces.

Results and models¶
CelebA-HQ
| Model | Mask Type | Resolution | Train Iters | Dataset | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|
| DeepFillv2 | free-form | 256x256 | 20k | CelebA-val | 5.411 | 25.721 | 0.871 | 8 | model | log |
Places365-Challenge
| Model | Mask Type | Resolution | Train Iters | Dataset | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|
| DeepFillv2 | free-form | 256x256 | 100k | Places365-val | 8.635 | 22.398 | 0.815 | 8 | model | log |
Quick Start¶
Train
Train Instructions
You can use the following commands to train a model with cpu or single/multiple GPUs.
## cpu train
CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/deepfillv2/deepfillv2_8xb2_places-256x256.py
## single-gpu train
python tools/train.py configs/deepfillv2/deepfillv2_8xb2_places-256x256.py
## multi-gpu train
./tools/dist_train.sh configs/deepfillv2/deepfillv2_8xb2_places-256x256.py 8
For more details, you can refer to Train a model part in train_test.md.
Test
Test Instructions
You can use the following commands to test a model with cpu or single/multiple GPUs.
## cpu test
CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/deepfillv2/deepfillv2_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth
## single-gpu test
python tools/test.py configs/deepfillv2/deepfillv2_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth
## multi-gpu test
./tools/dist_test.sh configs/deepfillv2/deepfillv2_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv2/deepfillv2_256x256_8x2_places_20200619-10d15793.pth 8
For more details, you can refer to Test a pre-trained model part in train_test.md.
Citation¶
@inproceedings{yu2019free,
title={Free-form image inpainting with gated convolution},
author={Yu, Jiahui and Lin, Zhe and Yang, Jimei and Shen, Xiaohui and Lu, Xin and Huang, Thomas S},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
pages={4471--4480},
year={2019}
}
PConv (ECCV’2018)¶
Task: Inpainting
Abstract¶
Existing deep learning based image inpainting methods use a standard convolutional network over the corrupted image, using convolutional filter responses conditioned on both valid pixels as well as the substitute values in the masked holes (typically the mean value). This often leads to artifacts such as color discrepancy and blurriness. Post-processing is usually used to reduce such artifacts, but are expensive and may fail. We propose the use of partial convolutions, where the convolution is masked and renormalized to be conditioned on only valid pixels. We further include a mechanism to automatically generate an updated mask for the next layer as part of the forward pass. Our model outperforms other methods for irregular masks. We show qualitative and quantitative comparisons with other methods to validate our approach.

Results and models¶
| Model | Mask Type | Resolution | Train Iters | Dataset | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|
| PConv_Stage1 | free-form | 256x256 | 500k | Places365-val | - | - | - | 8 | - |
| PConv_Stage2 | free-form | 256x256 | 500k | Places365-val | 8.776 | 22.762 | 0.801 | 4 | model | log |
| PConv_Stage1 | free-form | 256x256 | 500k | CelebA-val | - | - | - | 8 | - |
| PConv_Stage2 | free-form | 256x256 | 500k | CelebA-val | 5.990 | 25.404 | 0.853 | 4 | model | log |
Quick Start¶
Train
Train Instructions
You can use the following commands to train a model with cpu or single/multiple GPUs.
## cpu train
CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/partial_conv/pconv_stage2_4xb2_places-256x256.py
## single-gpu train
python tools/train.py configs/partial_conv/pconv_stage2_4xb2_places-256x256.py
## multi-gpu train
./tools/dist_train.sh configs/partial_conv/pconv_stage2_4xb2_places-256x256.py 8
For more details, you can refer to Train a model part in train_test.md.
Test
Test Instructions
You can use the following commands to test a model with cpu or single/multiple GPUs.
## cpu test
CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/partial_conv/pconv_stage2_4xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/pconv/pconv_256x256_stage2_4x2_places_20200619-1ffed0e8.pth
## single-gpu test
python tools/test.py configs/partial_conv/pconv_stage2_4xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/pconv/pconv_256x256_stage2_4x2_places_20200619-1ffed0e8.pth
## multi-gpu test
./tools/dist_test.sh configs/partial_conv/pconv_stage2_4xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/pconv/pconv_256x256_stage2_4x2_places_20200619-1ffed0e8.pth 8
For more details, you can refer to Test a pre-trained model part in train_test.md.
Citation¶
@inproceedings{liu2018image,
title={Image inpainting for irregular holes using partial convolutions},
author={Liu, Guilin and Reda, Fitsum A and Shih, Kevin J and Wang, Ting-Chun and Tao, Andrew and Catanzaro, Bryan},
booktitle={Proceedings of the European Conference on Computer Vision (ECCV)},
pages={85--100},
year={2018}
}
DeepFillv1 (CVPR’2018)¶
Task: Inpainting
Abstract¶
Recent deep learning based approaches have shown promising results for the challenging task of inpainting large missing regions in an image. These methods can generate visually plausible image structures and textures, but often create distorted structures or blurry textures inconsistent with surrounding areas. This is mainly due to ineffectiveness of convolutional neural networks in explicitly borrowing or copying information from distant spatial locations. On the other hand, traditional texture and patch synthesis approaches are particularly suitable when it needs to borrow textures from the surrounding regions. Motivated by these observations, we propose a new deep generative model-based approach which can not only synthesize novel image structures but also explicitly utilize surrounding image features as references during network training to make better predictions. The model is a feed-forward, fully convolutional neural network which can process images with multiple holes at arbitrary locations and with variable sizes during the test time. Experiments on multiple datasets including faces (CelebA, CelebA-HQ), textures (DTD) and natural images (ImageNet, Places2) demonstrate that our proposed approach generates higher-quality inpainting results than existing ones.

Results and models¶
CelebA-HQ
| Model | Mask Type | Resolution | Train Iters | Dataset | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|
| DeepFillv1 | square bbox | 256x256 | 1500k | CelebA-val | 6.677 | 26.878 | 0.911 | 4 | model | log |
Places365-Challenge
| Model | Mask Type | Resolution | Train Iters | Dataset | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|
| DeepFillv1 | square bbox | 256x256 | 3500k | Places365-val | 11.019 | 23.429 | 0.862 | 8 | model | log |
Quick Start¶
Train
Train Instructions
You can use the following commands to train a model with cpu or single/multiple GPUs.
## cpu train
CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/deepfillv1/deepfillv1_8xb2_places-256x256.py
## single-gpu train
python tools/train.py configs/deepfillv1/deepfillv1_8xb2_places-256x256.py
## multi-gpu train
./tools/dist_train.sh configs/deepfillv1/deepfillv1_8xb2_places-256x256.py 8
For more details, you can refer to Train a model part in train_test.md.
Test
Test Instructions
You can use the following commands to test a model with cpu or single/multiple GPUs.
## cpu test
CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/deepfillv1/deepfillv1_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth
## single-gpu test
python tools/test.py configs/deepfillv1/deepfillv1_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth
## multi-gpu test
./tools/dist_test.sh configs/deepfillv1/deepfillv1_8xb2_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/deepfillv1/deepfillv1_256x256_8x2_places_20200619-c00a0e21.pth 8
For more details, you can refer to Test a pre-trained model part in train_test.md.
Citation¶
@inproceedings{yu2018generative,
title={Generative image inpainting with contextual attention},
author={Yu, Jiahui and Lin, Zhe and Yang, Jimei and Shen, Xiaohui and Lu, Xin and Huang, Thomas S},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={5505--5514},
year={2018}
}
Global&Local (ToG’2017)¶
Task: Inpainting
Abstract¶
We present a novel approach for image completion that results in images that are both locally and globally consistent. With a fully-convolutional neural network, we can complete images of arbitrary resolutions by flling in missing regions of any shape. To train this image completion network to be consistent, we use global and local context discriminators that are trained to distinguish real images from completed ones. The global discriminator looks at the entire image to assess if it is coherent as a whole, while the local discriminator looks only at a small area centered at the completed region to ensure the local consistency of the generated patches. The image completion network is then trained to fool the both context discriminator networks, which requires it to generate images that are indistinguishable from real ones with regard to overall consistency as well as in details. We show that our approach can be used to complete a wide variety of scenes. Furthermore, in contrast with the patch-based approaches such as PatchMatch, our approach can generate fragments that do not appear elsewhere in the image, which allows us to naturally complete the image.

Results and models¶
Note that we do not apply the post-processing module in Global&Local for a fair comparison with current deep inpainting methods.
| Model | Dataset | Mask Type | Resolution | Train Iters | Test Set | l1 error | PSNR | SSIM | Training Resources | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| Global&Local | Places365-Challenge | square bbox | 256x256 | 500k | Places365-val | 11.164 | 23.152 | 0.862 | 8 | model | log |
| Global&Local | CelebA-HQ | square bbox | 256x256 | 500k | CelebA-val | 6.678 | 26.780 | 0.904 | 8 | model | log |
Quick Start¶
Train
Train Instructions
You can use the following commands to train a model with cpu or single/multiple GPUs.
## cpu train
CUDA_VISIBLE_DEVICES=-1 python tools/train.py configs/global_local/gl_8xb12_places-256x256.py
## single-gpu train
python tools/train.py configs/global_local/gl_8xb12_places-256x256.py
## multi-gpu train
./tools/dist_train.sh configs/global_local/gl_8xb12_places-256x256.py 8
For more details, you can refer to Train a model part in train_test.md.
Test
Test Instructions
You can use the following commands to test a model with cpu or single/multiple GPUs.
## cpu test
CUDA_VISIBLE_DEVICES=-1 python tools/test.py configs/global_local/gl_8xb12_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/global_local/gl_256x256_8x12_places_20200619-52a040a8.pth
## single-gpu test
python tools/test.py configs/global_local/gl_8xb12_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/global_local/gl_256x256_8x12_places_20200619-52a040a8.pth
## multi-gpu test
./tools/dist_test.sh configs/global_local/gl_8xb12_places-256x256.py https://download.openmmlab.com/mmediting/inpainting/global_local/gl_256x256_8x12_places_20200619-52a040a8.pth 8
For more details, you can refer to Test a pre-trained model part in train_test.md.
Citation¶
@article{iizuka2017globally,
title={Globally and locally consistent image completion},
author={Iizuka, Satoshi and Simo-Serra, Edgar and Ishikawa, Hiroshi},
journal={ACM Transactions on Graphics (ToG)},
volume={36},
number={4},
pages={1--14},
year={2017},
publisher={ACM New York, NY, USA}
}