unconditional gans¶
Summary¶
Number of checkpoints: 56
Number of configs: 57
Number of papers: 9
ALGORITHM: 9
StyleGANv3 (NeurIPS’2021)¶
Task: Unconditional GANs
Abstract¶
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.

Results and Models¶

We perform experiments on StyleGANv3 paper settings and also experimental settings. For user convenience, we also offer the converted version of official weights.
Paper Settings¶
| Model | Dataset | Iter | FID50k | Download |
|---|---|---|---|---|
| stylegan3-t | ffhq 1024x1024 | 490000 | 3.37* | ckpt | log |
| stylegan3-t-ada | metface 1024x1024 | 130000 | 15.09 | ckpt | log |
Experimental Settings¶
| Model | Dataset | Iter | FID50k | Download |
|---|---|---|---|---|
| stylegan3-t | ffhq 256x256 | 740000 | 4.51 | ckpt | log |
| stylegan3-r-ada | ffhq 1024x1024 | - | - | ckpt |
Converted Weights¶
| Model | Dataset | Comment | FID50k | EQ-T | EQ-R | Download |
|---|---|---|---|---|---|---|
| stylegan3-t | ffhqu 256x256 | official weight | 4.62 | 63.01 | 13.12 | ckpt |
| stylegan3-t | afhqv2 512x512 | official weight | 4.04 | 60.15 | 13.51 | ckpt |
| stylegan3-t | ffhq 1024x1024 | official weight | 2.79 | 61.21 | 13.82 | ckpt |
| stylegan3-r | ffhqu 256x256 | official weight | 4.50 | 66.65 | 40.48 | ckpt |
| stylegan3-r | afhqv2 512x512 | official weight | 4.40 | 64.89 | 40.34 | ckpt |
| stylegan3-r | ffhq 1024x1024 | official weight | 3.07 | 64.76 | 46.62 | ckpt |
Interpolation¶
We provide a tool to generate video by walking through GAN’s latent space. Run this command to get the following video.
python apps/interpolate_sample.py configs/styleganv3/stylegan3_t_afhqv2_512_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_t_afhqv2_512_b4x8_cvt_official.pkl --export-video --samples-path work_dirs/demos/ --endpoint 6 --interval 60 --space z --seed 2022 --sample-cfg truncation=0.8
https://user-images.githubusercontent.com/22982797/151506918-83da9ee3-0d63-4c5b-ad53-a41562b92075.mp4
Equivarience Visualization && Evaluation¶
We also provide a tool to visualize the equivarience properties for StyleGAN3. Run these commands to get the results below.
python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.5 --transform rotate --seed 5432
python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform x_t --seed 5432
python tools/utils/equivariance_viz.py configs/styleganv3/stylegan3_r_ffhqu_256_b4x8_official.py https://download.openmmlab.com/mmediting/stylegan3/stylegan3_r_ffhqu_256_b4x8_cvt_official.pkl --translate_max 0.25 --transform y_t --seed 5432
https://user-images.githubusercontent.com/22982797/151504902-f3cbfef5-9014-4607-bbe1-deaf48ec6d55.mp4
https://user-images.githubusercontent.com/22982797/151504973-b96e1639-861d-434b-9d7c-411ebd4a653f.mp4
https://user-images.githubusercontent.com/22982797/151505099-cde4999e-aab1-42d4-a458-3bb069db3d32.mp4
If you want to get EQ-Metric for StyleGAN3, just add following codes into config.
metrics = dict(
eqv=dict(
type='Equivariance',
num_images=50000,
eq_cfg=dict(
compute_eqt_int=True, compute_eqt_frac=True, compute_eqr=True)))
And we highly recommend you to use slurm_test.sh script to accelerate evaluation time.
Citation¶
@inproceedings{Karras2021,
author = {Tero Karras and Miika Aittala and Samuli Laine and Erik H\"ark\"onen and Janne Hellsten and Jaakko Lehtinen and Timo Aila},
title = {Alias-Free Generative Adversarial Networks},
booktitle = {Proc. NeurIPS},
year = {2021}
}
Positional Encoding in GANs (CVPR’2021)¶
Task: Unconditional GANs
Abstract¶
SinGAN shows impressive capability in learning internal patch distribution despite its limited effective receptive field. We are interested in knowing how such a translation-invariant convolutional generator could capture the global structure with just a spatially i.i.d. input. In this work, taking SinGAN and StyleGAN2 as examples, we show that such capability, to a large extent, is brought by the implicit positional encoding when using zero padding in the generators. Such positional encoding is indispensable for generating images with high fidelity. The same phenomenon is observed in other generative architectures such as DCGAN and PGGAN. We further show that zero padding leads to an unbalanced spatial bias with a vague relation between locations. To offer a better spatial inductive bias, we investigate alternative positional encodings and analyze their effects. Based on a more flexible positional encoding explicitly, we propose a new multi-scale training strategy and demonstrate its effectiveness in the state-of-the-art unconditional generator StyleGAN2. Besides, the explicit spatial inductive bias substantially improve SinGAN for more versatile image manipulation.

Results and models for MS-PIE¶
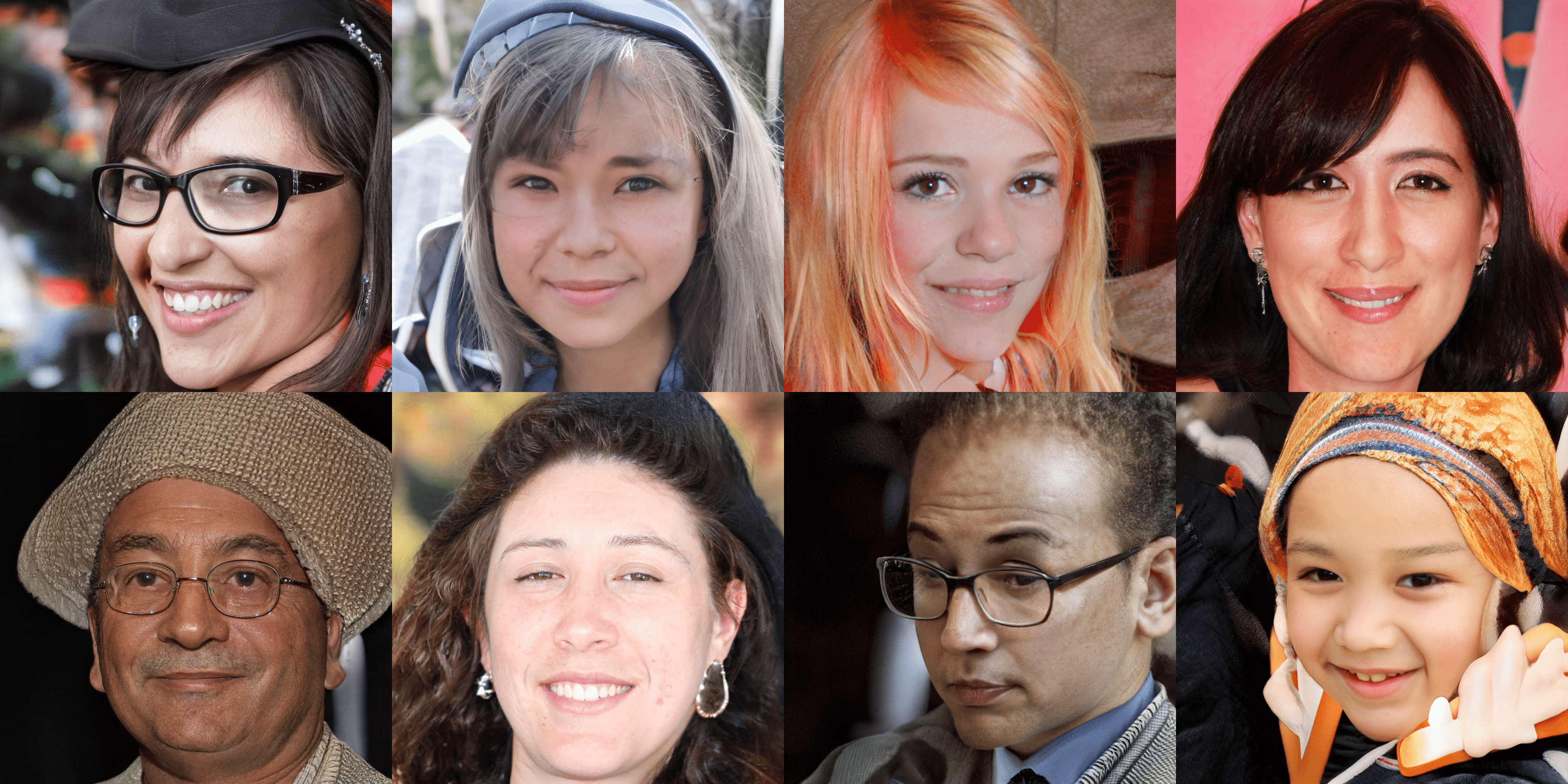
Note that we report the FID and P&R metric (FFHQ dataset) in the largest scale.
Results and Models for SinGAN¶

| Model | Dataset | Num Scales | Download |
|---|---|---|---|
| singan_interp-pad_balloons | balloons.png | 8 | ckpt | pkl |
| singan_interp-pad_disc-nobn_balloons | balloons.png | 8 | ckpt | pkl |
| singan_interp-pad_disc-nobn_fish | fish.jpg | 10 | ckpt | pkl |
| singan-csg_fish | fish.jpg | 10 | ckpt | pkl |
| singan-csg_bohemian | bohemian.png | 10 | ckpt | pkl |
| singan_spe-dim4_fish | fish.jpg | 10 | ckpt | pkl |
| singan_spe-dim4_bohemian | bohemian.png | 10 | ckpt | pkl |
| singan_spe-dim8_bohemian | bohemian.png | 10 | ckpt | pkl |
{kind=link}
{kind=link}
{kind=link}
Citation¶
@article{xu2020positional,
title={Positional Encoding as Spatial Inductive Bias in GANs},
author={Xu, Rui and Wang, Xintao and Chen, Kai and Zhou, Bolei and Loy, Chen Change},
journal={arXiv preprint arXiv:2012.05217},
year={2020},
url={https://openaccess.thecvf.com/content/CVPR2021/html/Xu_Positional_Encoding_As_Spatial_Inductive_Bias_in_GANs_CVPR_2021_paper.html},
}
StyleGANv2 (CVPR’2020)¶
Task: Unconditional GANs
Abstract¶
The style-based GAN architecture (StyleGAN) yields state-of-the-art results in data-driven unconditional generative image modeling. We expose and analyze several of its characteristic artifacts, and propose changes in both model architecture and training methods to address them. In particular, we redesign the generator normalization, revisit progressive growing, and regularize the generator to encourage good conditioning in the mapping from latent codes to images. In addition to improving image quality, this path length regularizer yields the additional benefit that the generator becomes significantly easier to invert. This makes it possible to reliably attribute a generated image to a particular network. We furthermore visualize how well the generator utilizes its output resolution, and identify a capacity problem, motivating us to train larger models for additional quality improvements. Overall, our improved model redefines the state of the art in unconditional image modeling, both in terms of existing distribution quality metrics as well as perceived image quality.

Results and Models¶

| Model | Dataset | Comment | FID50k | Precision50k | Recall50k | Download |
|---|---|---|---|---|---|---|
| stylegan2_c2_8xb4_ffhq-1024x1024 | FFHQ | official weight | 2.8134 | 62.856 | 49.400 | model |
| stylegan2_c2_8xb4_lsun-car-384x512 | LSUN_CAR | official weight | 5.4316 | 65.986 | 48.190 | model |
| stylegan2_c2_8xb4-800kiters_lsun-horse-256x256 | LSUN_HORSE | official weight | - | - | - | model |
| stylegan2_c2_8xb4-800kiters_lsun-church-256x256 | LSUN_CHURCH | official weight | - | - | - | model |
| stylegan2_c2_8xb4-800kiters_lsun-cat-256x256 | LSUN_CAT | official weight | - | - | - | model |
| stylegan2_c2_8xb4-800kiters_ffhq-256x256 | FFHQ | our training | 3.992 | 69.012 | 40.417 | model |
| stylegan2_c2_8xb4_ffhq-1024x1024 | FFHQ | our training | 2.8185 | 68.236 | 49.583 | model |
| stylegan2_c2_8xb4_lsun-car-384x512 | LSUN_CAR | our training | 2.4116 | 66.760 | 50.576 | model |
FP16 Support and Experiments¶
Currently, we have supported FP16 training for StyleGAN2, and here are the results for the mixed-precision training. (Experiments for FFHQ1024 will come soon.)

As shown in the figure, we provide 3 ways to do mixed-precision training for StyleGAN2:
stylegan2_c2_fp16_PL-no-scaler: In this setting, we try our best to follow the official FP16 implementation in StyleGAN2-ADA. Similar to the official version, we only adopt FP16 training for the higher-resolution feature maps (the last 4 stages in G and the first 4 stages). Note that we do not adopt the
clampway to avoid gradient overflow used in the official implementation. We use theautocastfunction fromtorch.cuda.amppackage.stylegan2_c2_fp16-globalG-partialD_PL-R1-no-scaler: In this config, we try to adopt mixed-precision training for the whole generator, but in partial discriminator (the first 4 higher-resolution stages). Note that we do not apply the loss scaler in the path length loss and gradient penalty loss. Because we always meet divergence after adopting the loss scaler to scale the gradient in these two losses.
stylegan2_c2_apex_fp16_PL-R1-no-scaler: In this setting, we adopt the APEX toolkit to implement mixed-precision training with multiple loss/gradient scalers. In APEX, you can assign different loss scalers for the generator and the discriminator respectively. Note that we still ignore the gradient scaler in the path length loss and gradient penalty loss.
| Model | Comment | Dataset | FID50k | Download |
|---|---|---|---|---|
| stylegan2_c2_8xb4-800kiters_ffhq-256x256 | baseline | FFHQ256 | 3.992 | ckpt |
| stylegan2_c2-PL_8xb4-fp16-partial-GD-no-scaler-800kiters_ffhq-256x256 | partial layers in fp16 | FFHQ256 | 4.331 | ckpt |
| stylegan2_c2-PL-R1_8xb4-fp16-globalG-partialD-no-scaler-800kiters_ffhq-256x256 | the whole G in fp16 | FFHQ256 | 4.362 | ckpt |
| stylegan2_c2-PL-R1_8xb4-apex-fp16-no-scaler-800kiters_ffhq-256x256 | the whole G&D in fp16 + two loss scaler | FFHQ256 | 4.614 | ckpt |
As shown in this table, P&R50k_full is the metric used in StyleGANv1 and StyleGANv2. full indicates that we use the whole dataset for extracting the real distribution, e.g., 70000 images in FFHQ dataset. However, adopting the VGG16 provided from Tero requires that your PyTorch version must fulfill >=1.6.0. Be careful about using the PyTorch’s VGG16 to extract features, which will cause higher precision and recall.
Citation¶
@inproceedings{karras2020analyzing,
title={Analyzing and improving the image quality of stylegan},
author={Karras, Tero and Laine, Samuli and Aittala, Miika and Hellsten, Janne and Lehtinen, Jaakko and Aila, Timo},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8110--8119},
year={2020},
url={https://openaccess.thecvf.com/content_CVPR_2020/html/Karras_Analyzing_and_Improving_the_Image_Quality_of_StyleGAN_CVPR_2020_paper.html},
}
StyleGANv1 (CVPR’2019)¶
Task: Unconditional GANs
Abstract¶
We propose an alternative generator architecture for generative adversarial networks, borrowing from style transfer literature. The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis. The new generator improves the state-of-the-art in terms of traditional distribution quality metrics, leads to demonstrably better interpolation properties, and also better disentangles the latent factors of variation. To quantify interpolation quality and disentanglement, we propose two new, automated methods that are applicable to any generator architecture. Finally, we introduce a new, highly varied and high-quality dataset of human faces.

Results and Models¶

| Model | Dataset | FID50k | P&R50k_full | Download |
|---|---|---|---|---|
| styleganv1_ffhq_256 | FFHQ | 6.090 | 70.228/27.050 | model |
| styleganv1_ffhq_1024 | FFHQ | 4.056 | 70.302/36.869 | model |
Citation¶
@inproceedings{karras2019style,
title={A style-based generator architecture for generative adversarial networks},
author={Karras, Tero and Laine, Samuli and Aila, Timo},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={4401--4410},
year={2019},
url={https://openaccess.thecvf.com/content_CVPR_2019/html/Karras_A_Style-Based_Generator_Architecture_for_Generative_Adversarial_Networks_CVPR_2019_paper.html},
}
PGGAN (ICLR’2018)¶
Task: Unconditional GANs
Abstract¶
We describe a new training methodology for generative adversarial networks. The key idea is to grow both the generator and discriminator progressively: starting from a low resolution, we add new layers that model increasingly fine details as training progresses. This both speeds the training up and greatly stabilizes it, allowing us to produce images of unprecedented quality, e.g., CelebA images at 1024^2. We also propose a simple way to increase the variation in generated images, and achieve a record inception score of 8.80 in unsupervised CIFAR10. Additionally, we describe several implementation details that are important for discouraging unhealthy competition between the generator and discriminator. Finally, we suggest a new metric for evaluating GAN results, both in terms of image quality and variation. As an additional contribution, we construct a higher-quality version of the CelebA dataset.

Results and models¶

| Model | Dataset | MS-SSIM | SWD(xx,xx,xx,xx/avg) | Download |
|---|---|---|---|---|
| pggan_128x128 | celeba-cropped | 0.3023 | 3.42, 4.04, 4.78, 20.38/8.15 | model |
| pggan_128x128 | lsun-bedroom | 0.0602 | 3.5, 2.96, 2.76, 9.65/4.72 | model |
| pggan_1024x1024 | celeba-hq | 0.3379 | 8.93, 3.98, 3.07, 2.64/4.655 | model |
Citation¶
@article{karras2017progressive,
title={Progressive growing of gans for improved quality, stability, and variation},
author={Karras, Tero and Aila, Timo and Laine, Samuli and Lehtinen, Jaakko},
journal={arXiv preprint arXiv:1710.10196},
year={2017},
url={https://arxiv.org/abs/1710.10196},
}
GGAN (ArXiv’2017)¶
Task: Unconditional GANs
Abstract¶
Generative Adversarial Nets (GANs) represent an important milestone for effective generative models, which has inspired numerous variants seemingly different from each other. One of the main contributions of this paper is to reveal a unified geometric structure in GAN and its variants. Specifically, we show that the adversarial generative model training can be decomposed into three geometric steps: separating hyperplane search, discriminator parameter update away from the separating hyperplane, and the generator update along the normal vector direction of the separating hyperplane. This geometric intuition reveals the limitations of the existing approaches and leads us to propose a new formulation called geometric GAN using SVM separating hyperplane that maximizes the margin. Our theoretical analysis shows that the geometric GAN converges to a Nash equilibrium between the discriminator and generator. In addition, extensive numerical results show that the superior performance of geometric GAN.

Results and models¶

| Model | Dataset | SWD | MS-SSIM | FID | Download |
|---|---|---|---|---|---|
| GGAN 64x64 | CelebA-Cropped | 11.18, 12.21, 39.16/20.85 | 0.3318 | 20.1797 | model | log |
| GGAN 128x128 | CelebA-Cropped | 9.81, 11.29, 19.22, 47.79/22.03 | 0.3149 | 18.7647 | model | log |
| GGAN 64x64 | LSUN-Bedroom | 9.1, 6.2, 12.27/9.19 | 0.0649 | 39.9261 | model | log |
Note: In the original implementation of GGAN, they set G_iters to 10. However our framework does not support G_iters currently, so we dropped the settings in the original implementation and conducted several experiments with our own settings. We have shown above the experiment results with the lowest fid score.
Original settings and our settings:
| Model | Dataset | Architecture | optimizer | lr_G | lr_D | G_iters | D_iters |
|---|---|---|---|---|---|---|---|
| GGAN(origin) 64x64 | CelebA-Cropped | dcgan-archi | RMSprop | 0.0002 | 0.0002 | 10 | 1 |
| GGAN(ours) 64x64 | CelebA-Cropped | dcgan-archi | Adam | 0.001 | 0.001 | 1 | 1 |
| GGAN(origin) 64x64 | LSUN-Bedroom | dcgan-archi | RMSprop | 0.0002 | 0.0002 | 10 | 1 |
| GGAN(ours) 64x64 | LSUN-Bedroom | lsgan-archi | Adam | 0.0001 | 0.0001 | 1 | 1 |
Citation¶
@article{lim2017geometric,
title={Geometric gan},
author={Lim, Jae Hyun and Ye, Jong Chul},
journal={arXiv preprint arXiv:1705.02894},
year={2017},
url={https://arxiv.org/abs/1705.02894},
}
WGAN-GP (NeurIPS’2017)¶
Task: Unconditional GANs
Abstract¶
Generative Adversarial Networks (GANs) are powerful generative models, but suffer from training instability. The recently proposed Wasserstein GAN (WGAN) makes progress toward stable training of GANs, but sometimes can still generate only low-quality samples or fail to converge. We find that these problems are often due to the use of weight clipping in WGAN to enforce a Lipschitz constraint on the critic, which can lead to undesired behavior. We propose an alternative to clipping weights: penalize the norm of gradient of the critic with respect to its input. Our proposed method performs better than standard WGAN and enables stable training of a wide variety of GAN architectures with almost no hyperparameter tuning, including 101-layer ResNets and language models over discrete data. We also achieve high quality generations on CIFAR-10 and LSUN bedrooms.

Results and models¶

| Model | Dataset | Details | SWD | MS-SSIM | Download |
|---|---|---|---|---|---|
| WGAN-GP 128 | CelebA-Cropped | GN | 5.87, 9.76, 9.43, 18.84/10.97 | 0.2601 | model |
| WGAN-GP 128 | LSUN-Bedroom | GN, GP-lambda = 50 | 11.7, 7.87, 9.82, 25.36/13.69 | 0.059 | model |
Citation¶
@article{gulrajani2017improved,
title={Improved Training of Wasserstein GANs},
author={Gulrajani, Ishaan and Ahmed, Faruk and Arjovsky, Martin and Dumoulin, Vincent and Courville, Aaron},
journal={arXiv preprint arXiv:1704.00028},
year={2017},
url={https://arxiv.org/abs/1704.00028},
}
LSGAN (ICCV’2017)¶
Task: Unconditional GANs
Abstract¶
Unsupervised learning with generative adversarial networks (GANs) has proven hugely successful. Regular GANs hypothesize the discriminator as a classifier with the sigmoid cross entropy loss function. However, we found that this loss function may lead to the vanishing gradients problem during the learning process. To overcome such a problem, we propose in this paper the Least Squares Generative Adversarial Networks (LSGANs) which adopt the least squares loss function for the discriminator. We show that minimizing the objective function of LSGAN yields minimizing the Pearson χ2 divergence. There are two benefits of LSGANs over regular GANs. First, LSGANs are able to generate higher quality images than regular GANs. Second, LSGANs perform more stable during the learning process. We evaluate LSGANs on five scene datasets and the experimental results show that the images generated by LSGANs are of better quality than the ones generated by regular GANs. We also conduct two comparison experiments between LSGANs and regular GANs to illustrate the stability of LSGANs.

Results and models¶

| Model | Dataset | SWD | MS-SSIM | FID | Download |
|---|---|---|---|---|---|
| LSGAN 64x64 | CelebA-Cropped | 6.16, 6.83, 37.64/16.87 | 0.3216 | 11.9258 | model| log |
| LSGAN 64x64 | LSUN-Bedroom | 5.66, 9.0, 18.6/11.09 | 0.0671 | 30.7390 | model| log |
| LSGAN 128x128 | CelebA-Cropped | 21.66, 9.83, 16.06, 70.76/29.58 | 0.3691 | 38.3752 | model| log |
| LSGAN 128x128 | LSUN-Bedroom | 19.52, 9.99, 7.48, 14.3/12.82 | 0.0612 | 51.5500 | model| log |
Citation¶
@inproceedings{mao2017least,
title={Least squares generative adversarial networks},
author={Mao, Xudong and Li, Qing and Xie, Haoran and Lau, Raymond YK and Wang, Zhen and Paul Smolley, Stephen},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={2794--2802},
year={2017},
url={https://openaccess.thecvf.com/content_iccv_2017/html/Mao_Least_Squares_Generative_ICCV_2017_paper.html},
}
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (ICLR’2016)¶
Task: Unconditional GANs
Abstract¶
In recent years, supervised learning with convolutional networks (CNNs) has seen huge adoption in computer vision applications. Comparatively, unsupervised learning with CNNs has received less attention. In this work we hope to help bridge the gap between the success of CNNs for supervised learning and unsupervised learning. We introduce a class of CNNs called deep convolutional generative adversarial networks (DCGANs), that have certain architectural constraints, and demonstrate that they are a strong candidate for unsupervised learning. Training on various image datasets, we show convincing evidence that our deep convolutional adversarial pair learns a hierarchy of representations from object parts to scenes in both the generator and discriminator. Additionally, we use the learned features for novel tasks - demonstrating their applicability as general image representations.

Results and models¶

| Model | Dataset | SWD | MS-SSIM | Download |
|---|---|---|---|---|
| DCGAN 64x64 | MNIST (64x64) | 21.16, 4.4, 8.41/11.32 | 0.1395 | model | log |
| DCGAN 64x64 | CelebA-Cropped | 8.93,10.53,50.32/23.26 | 0.2899 | model | log |
| DCGAN 64x64 | LSUN-Bedroom | 42.79, 34.55, 98.46/58.6 | 0.2095 | model | log |
Citation¶
@article{radford2015unsupervised,
title={Unsupervised representation learning with deep convolutional generative adversarial networks},
author={Radford, Alec and Metz, Luke and Chintala, Soumith},
journal={arXiv preprint arXiv:1511.06434},
year={2015},
url={https://arxiv.org/abs/1511.06434},
}